
In 2018 I ran a quick test to find out if an HTML canonical tag and the rel=”canonical” HTTP header are analysed at the same speed in Google’s index.
TL; DR
I ran an experiment to see which would be faster the HTML canonical tag or the rel="canonical" HTTP header.
What I learned from this experiment was that:
- HTTP Header is faster – The
rel="canonical"HTTP header is faster at being picked up than the rel=”canonical” HTML tag (by 3 days). - Google is efficient at picking up signals – Googlebot’s crawling and indexing infrastructure is designed to pick up signals efficiently, which means that signals in the HTTP header that are picked up sooner are processed quicker than the HTML or rendered HTML.
- Use methods appropriately – The use of the
rel="canonical"HTTP header needs to be used appropriately and when needed, as a method you could combine with XML Sitemap chunking to reduce deduplication faster.
Right, onto the experiment and detail of the experiment.
The Canonical Race Test
The test itself was relatively simple.
I create four pages, 2 unique pages (A and B), and 2 duplicates of each unique page (C and D).
I then added a canonical HTML tag onto duplicate page C and pointed it to unique page A. For duplicate page D I configured my server to add a rel=”canonical” HTTP header and pointed the link to unique page B.
I then submitted all pages A, B, C, and D to Google using the Fetch and Render Tool (it was still accessible at that stage).
Hypothesis
The hypothesis for the test was fairly simple: Google processes both canonical methods at the same speed.
Canonical Race Results
When checking the results a few days later I noticed that both duplicate pages C and D had been crawled on the same date.
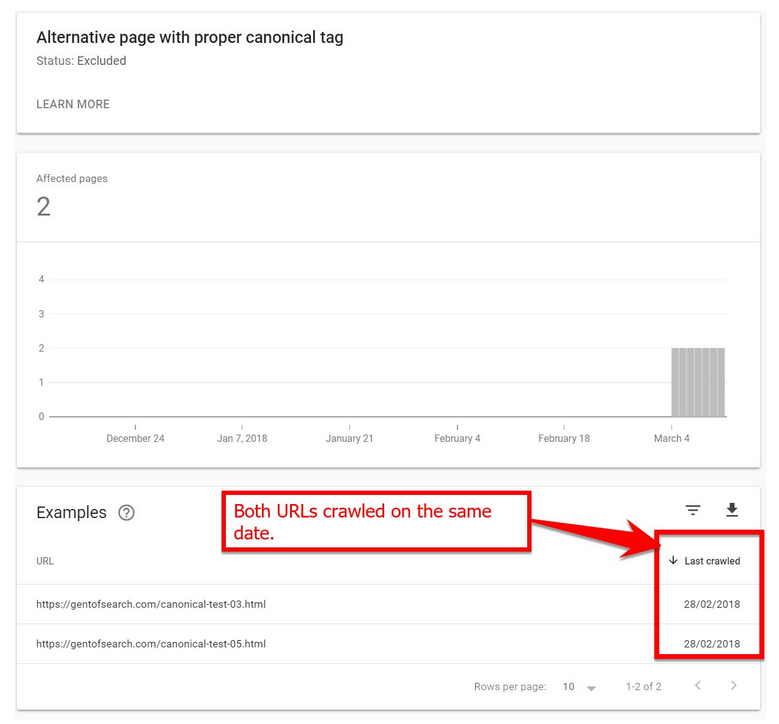
A few days later I was surprised to find that Google had analysed and processed duplicate page D with the rel=”canonical” HTTP header, and updated the Index Coverage report for the URL and labelled it as “Alternative page with the proper canonical tag”.
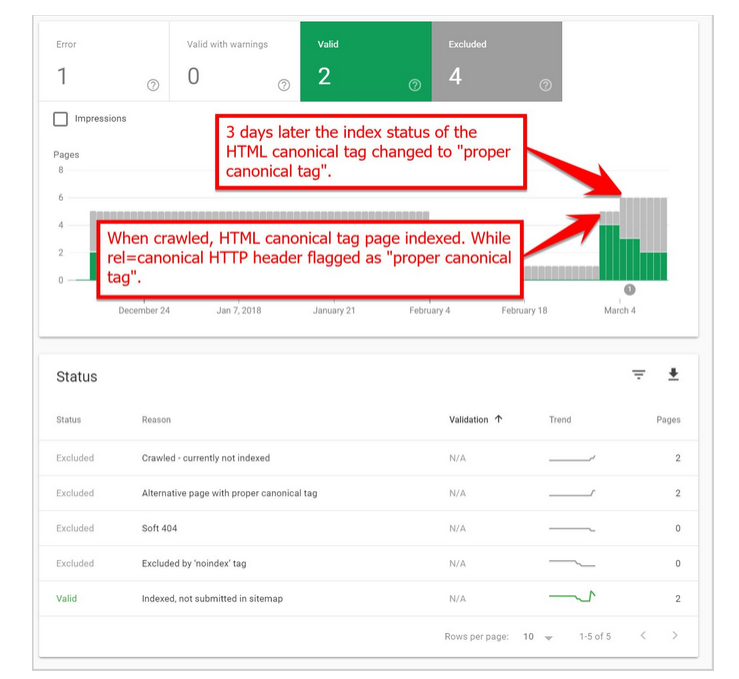
Google picked up the other HTML canonical tag 3 days later and displayed it as an “Alternative page with the proper canonical tag”. Although it was interesting that, at the time, the Index Coverage report labelled the duplicate URL as indexed until the canonical HTML tag was picked up.
Test Conclusion
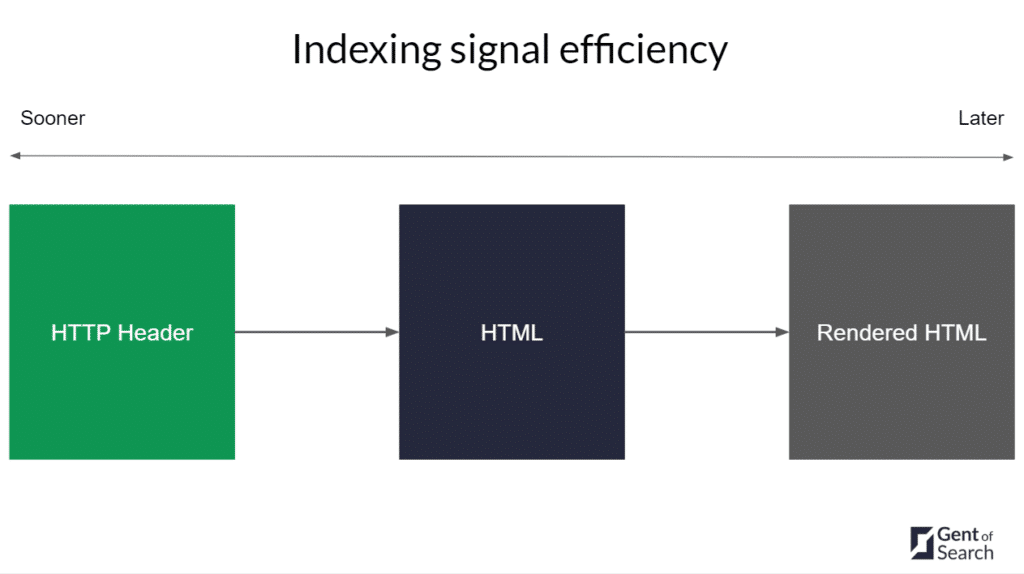
Based on my test the results show that Google’s indexing systems pick up canonical link signals in HTTP response headers faster than HTML tags.
Why did Google use the HTTP Header canonical link first?
I suspect this is due to HTTP response header attributes being processed first before HTML in Google’s crawling and indexing pipeline.
For example, if you do a cURL -i command on a live page on a website you can see that the HTTP Header is downloaded with the HTML.
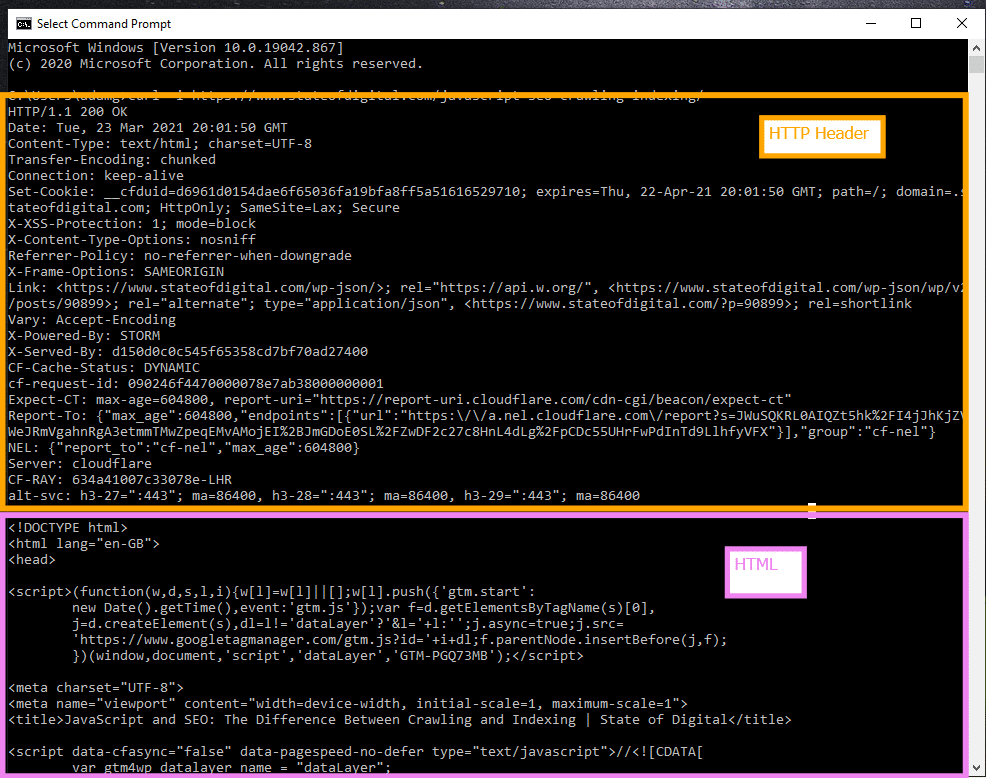
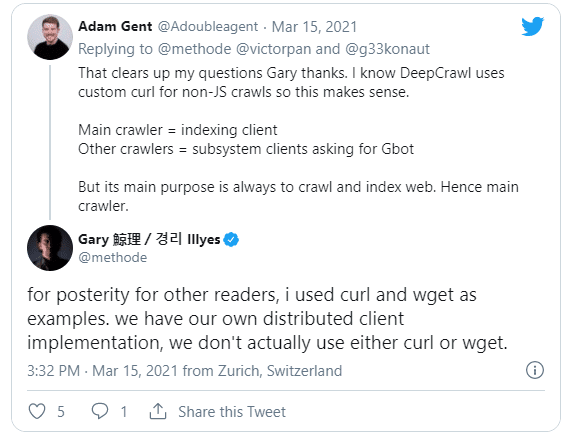
I imagine Googlebot does something similar, as Gary mentioned that it is built using a custom implementation similar to cURL.
At TechSEO Boost 2019 Martin Splitt talked about how the Web Rendering Service (WRS) is just one of many microservices in Google’s crawling and indexing system.

In his talk, he mentions that these microservices talk to each other as sometimes a URL might fail but need to be retried.
So, URLs might not always go through the exact same process or queue but for every URL the infrastructure collects signals as efficiently as it can.
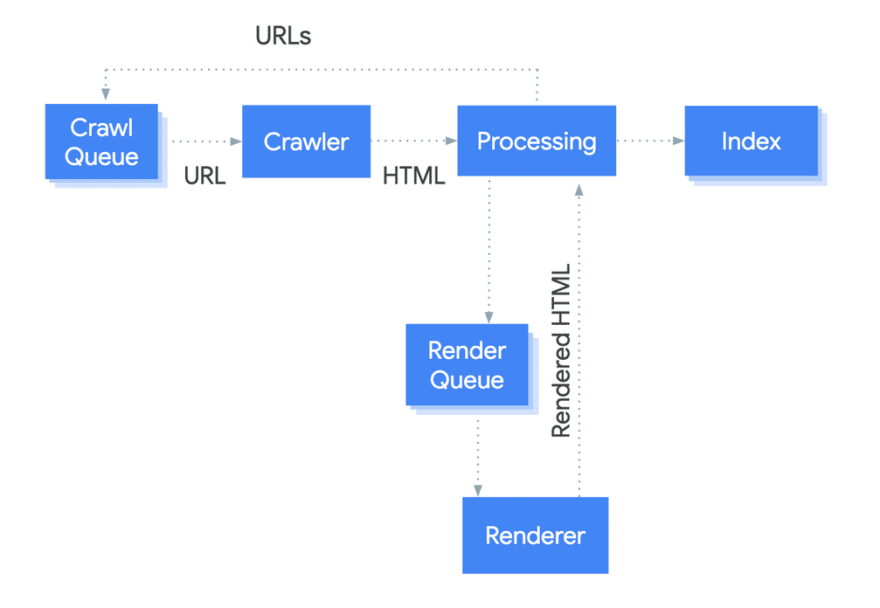
We know Googlebot analyses and extracts attributes from HTTP response headers, as the HTTP protocol is a critical part of how servers and clients communicate with each other.
I suspect that there is a microservice like an HTTP header parser quite early on in the indexing pipeline that picks up rel="canonical" link signals. This strong canonical signal for duplicate URLs can be used sooner in the deduplication microservice, as the system can be more efficient.
For the rel="canonical" HTML tag the deduplication microservice needs to wait until the HTML parser and WRS microservice need to parse and render the content and metadata in the HTML (which takes time).
Faster approach to deindexing duplicate content
Do I think SEOs and developers should start using just canonical links in the HTTP Header response?
Nope.
It’s important you make sure that you use the solution that helps you get the job done. If that is using classic HTML tags then go for it (I will), if you use HTTP header links then keep at it.
I personally would want to combine this technique with XML Sitemap hack to see if these two techniques can help get a large amount of duplicate content crawled and analysed faster.
If a canonical implementation strategy can be picked up quicker by Google, and less low-value URLs are de-indexed, then this can result in a positive impact on a website’s SEO performance overall.