
For the last few months, I’ve teamed up with a senior developer to play around with the URL Inspection API. Our goal was to see if we could create an indexing monitoring tool by storing the daily fetch requests from the URL Inspection API.
TL;DR
Indexing Monitoring Tool
- I’m working with a co-founder to build an indexing monitoring tool using the URL Inspection API.
- We’ve figured out how to monitor the indexing of websites at scale (e.g. 300,000 URLs in 30 days).
- You can learn more about the alpha version and sign up for the beta here.
Lessons from playing around with the URL Inspection API
- Redirects help get pages crawled and indexed faster
- Google doesn’t need to recrawl a URL to drop it from the index.
- Noindexed pages can turn into Crawled – currently not indexed pages
- An indexed page can drop out of Google’s index without any warning.
- Google can index low-value pages and slowly drop them from the index
Just like all adventures, this one starts with an exciting incident.
An important page on The SEO Sprint dropped out of Google’s index. And with Zero warning.
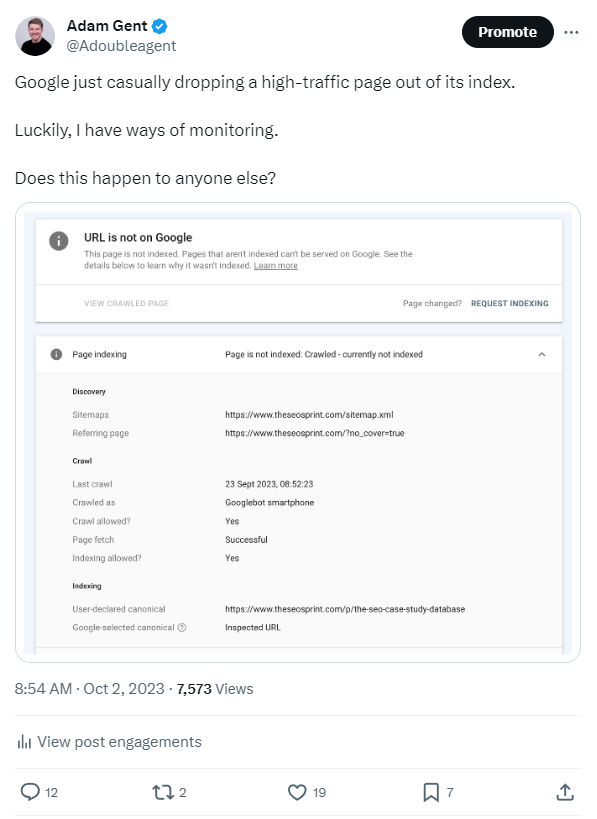
I posted the findings on Twitter, and as usual, many SEOs in the public group chat gave me their opinions. However, some shared their experiences of pages dropping out of the index.
Although many SEOs gave their opinions about why my page had been dropped. What bothered me the most was that Google Search Console didn’t alert me to this problem.
Reflecting on the tool, I realised that monitoring indexing over time for any website can be painful for analysing important page URLs on a website:
- The data is always 3 days behind.
- The data isn’t easily segmented (even when using sitemaps)
- The URL Inspection tool only gives you a snapshot in time
- The data is a mix of unimportant and important pages.
- There is no alert system for important pages being deindexed.
Don’t get me wrong — Google’s Search Console is incredibly powerful and useful. But it’s still free, and it has its issues.
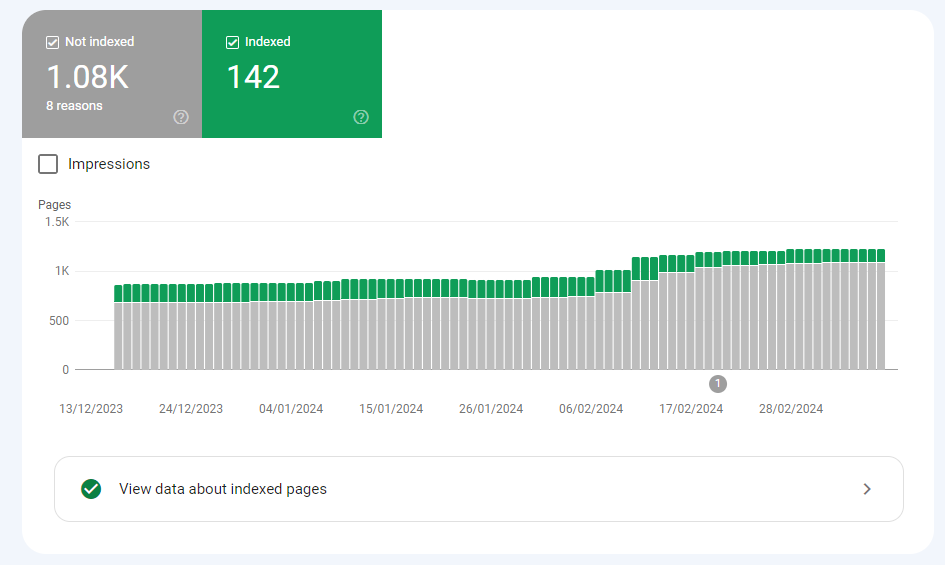
Note: A month ago, I migrated www.theseosprint.com to newsletter.theseosprint.com. I submitted the XML Sitemap to GSC but still can’t filter it in the Indexing > Pages report. I think this is a bug, but it still shows the unpredictability of a free tool. It’s been a month. Why is it taking so long to pull through the filter?
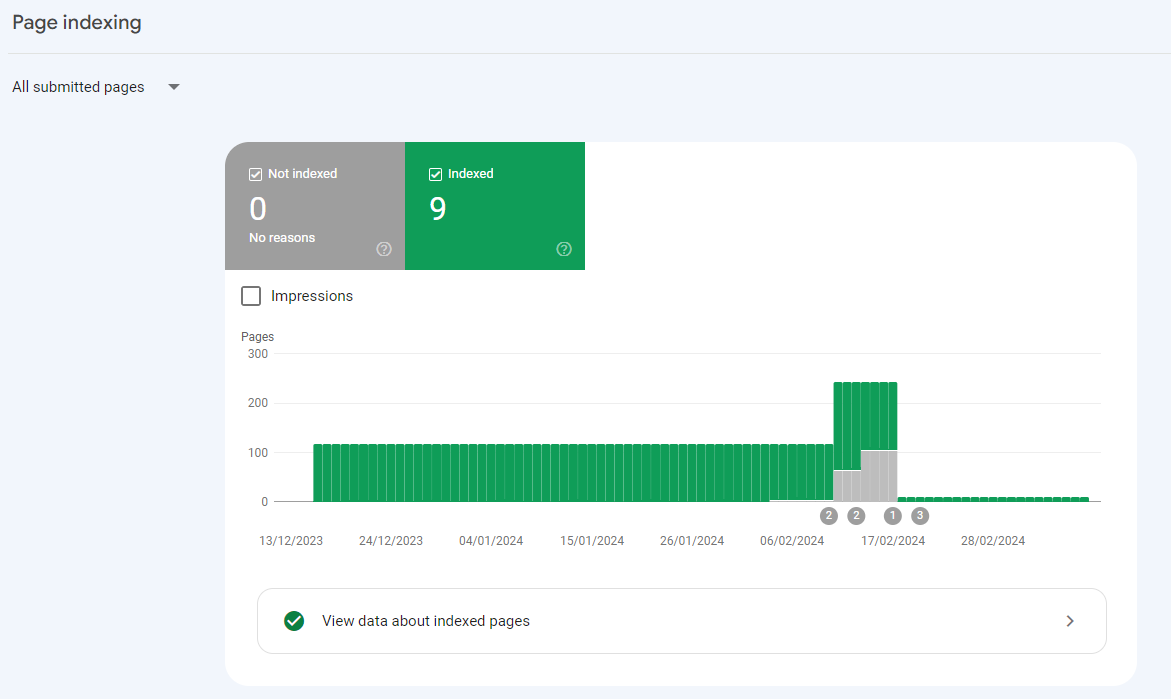
I set off to answer a simple question: Can you monitor the indexing of important pages on a website?
Index Monitoring Prototype
I know a few people who could build a prototype. So, I hired a developer to build a basic index monitoring tool prototype.
It was a simple tool:
- Extract important URLs from an XML Sitemap(s)
- Fetch the URLs daily using the URL Inspection API
- Store the daily information of each URL in the database
- Create a basic app that allowed me to view the raw data
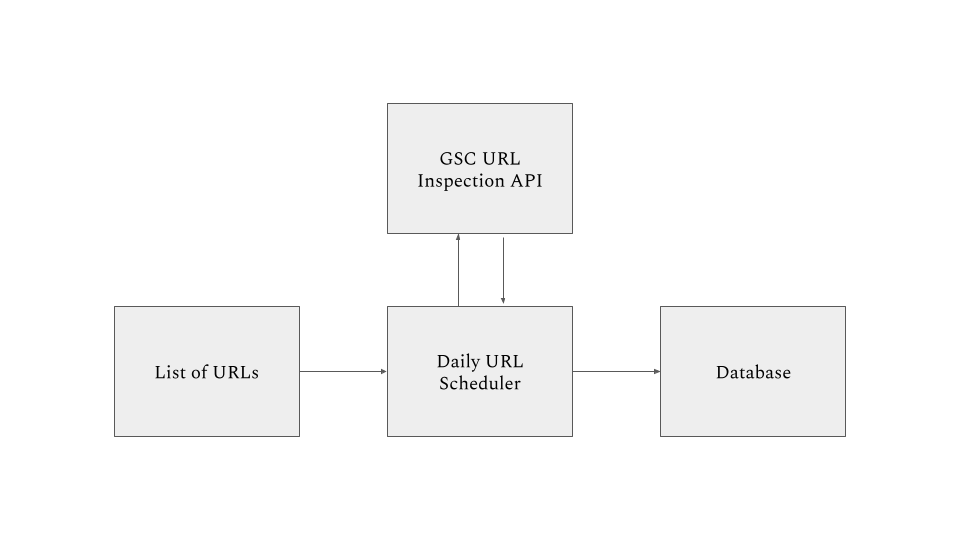 But it was very effective. Thanks to the support of the developer I hired, the monitoring tool prototype was created.
But it was very effective. Thanks to the support of the developer I hired, the monitoring tool prototype was created.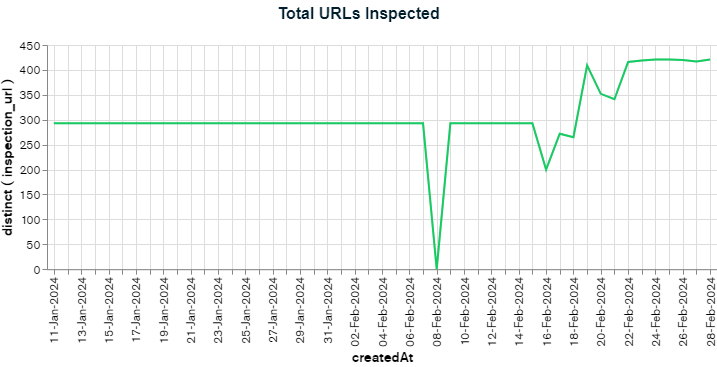
It taught me more about Google indexing and reporting. And what I found surprised me.
Analysing the historic indexing data
The tool allowed me to view the index status of The SEO Sprint over time. But I realised quickly that you could view indexing status at a:
- Website level – The data allowed me to view the indexing status of the entire website.
- Folder/subdomain level – The data allowed me to filter the specific site sections.
- Page URL level – The data allowed me to look at page-level indexing status over time.
Website indexing status
When I pulled The SEO Sprint indexing status from the tool, I saw a clear trend: The number of pages indexed was declining.

Which was a surprise. I expected it to go up and down…but an obvious gradual decline? Time to dig a little deeper!
Folder/subdomain indexing status
I segmented the indexing data by folder path and subdomain. You might not be able to see it in the graph, but I noticed that the learn.theseosprint.com subdomain was in decline.

Looking at the data, I immediately asked myself a simple question: Why were so many page URLs indexed on this domain section?
I wondered why so many URLs were being fetched and indexed. The Teachable platform was only meant to have 3-8 pages.
I reviewed the URLs in this website section and immediately found the answer. 
These page types shouldn’t have been indexed in the first place.
The Teachable platform created URLs for each lesson in all my courses. However, the content on each URL was “locked”. Google could discover, crawl, and index these pages because my school is linked to www.theseosprint.com.
And for some bizarre reason, Google decided these pages were worth indexing (they’re not). So, I witnessed in the indexing data that Google’s index is slowly kicking the URLs out.
I decided to investigate the indexing data at a page URL level.
URL indexing status
Filtering down to the particular pages within learn.theseosprint.com, you can see the indexing data that has been fetched over time.
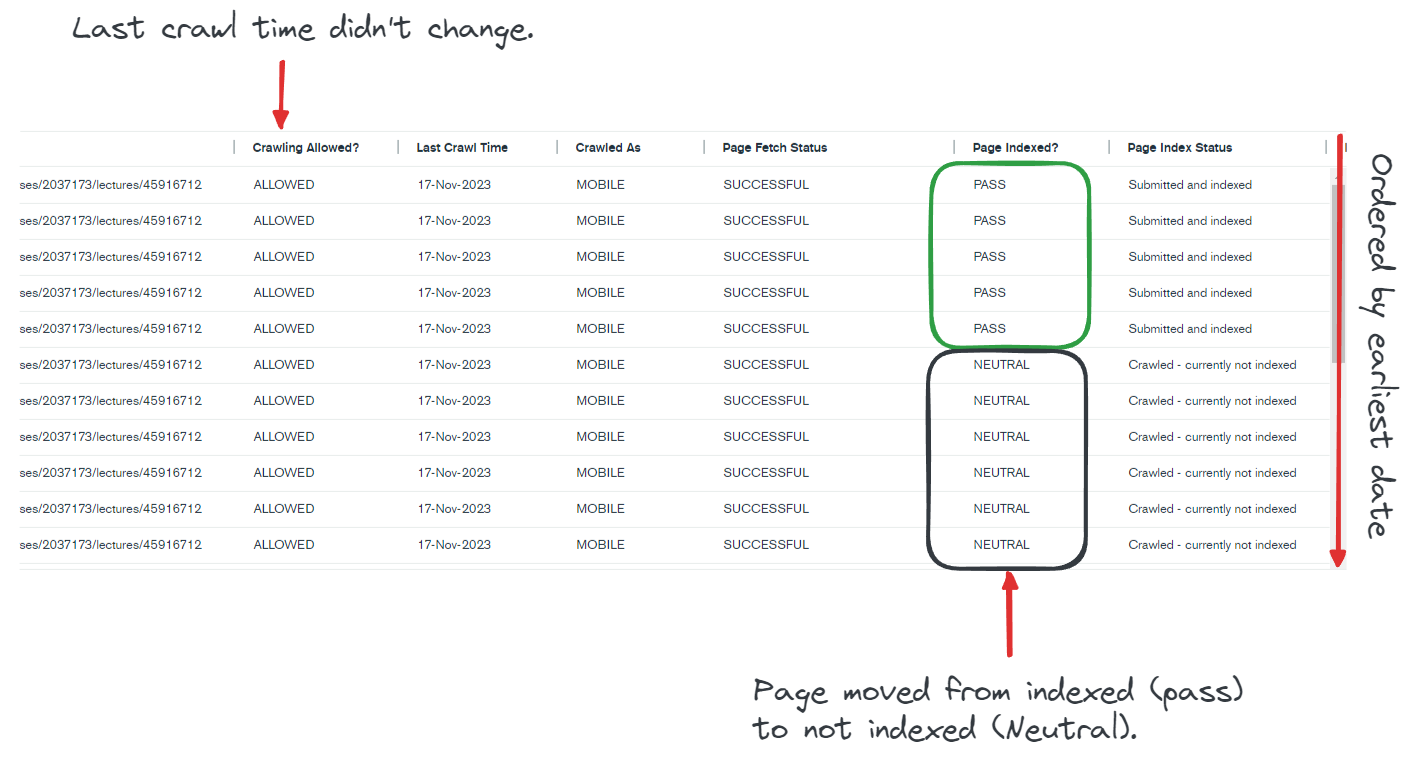
The most striking trends that jumped out at me when reviewing the data for individual URLs:
- The URL index status changed from Passed (Indexed) to Neutral (Excluded) within 1 day with no warning from GSC
- The page was moved from Submitted and Indexed to Crawled – currently not indexed within 1 day with no warning from GSC
- The Last Crawl Time of the URL did not change – indicating that recrawling a URL is not necessary to update the index coverage status in the system
Again, there is no doubt that Google should not have indexed these pages. But what I find interesting is that when you map the data over time, you gain useful insights.
Lessons learned from historic indexing data
The indexing data over time helped me better understand the crawling and indexing processes on The SEO Sprint website.
Every SEO professional has a basic grasp of how search engines crawl and index content…
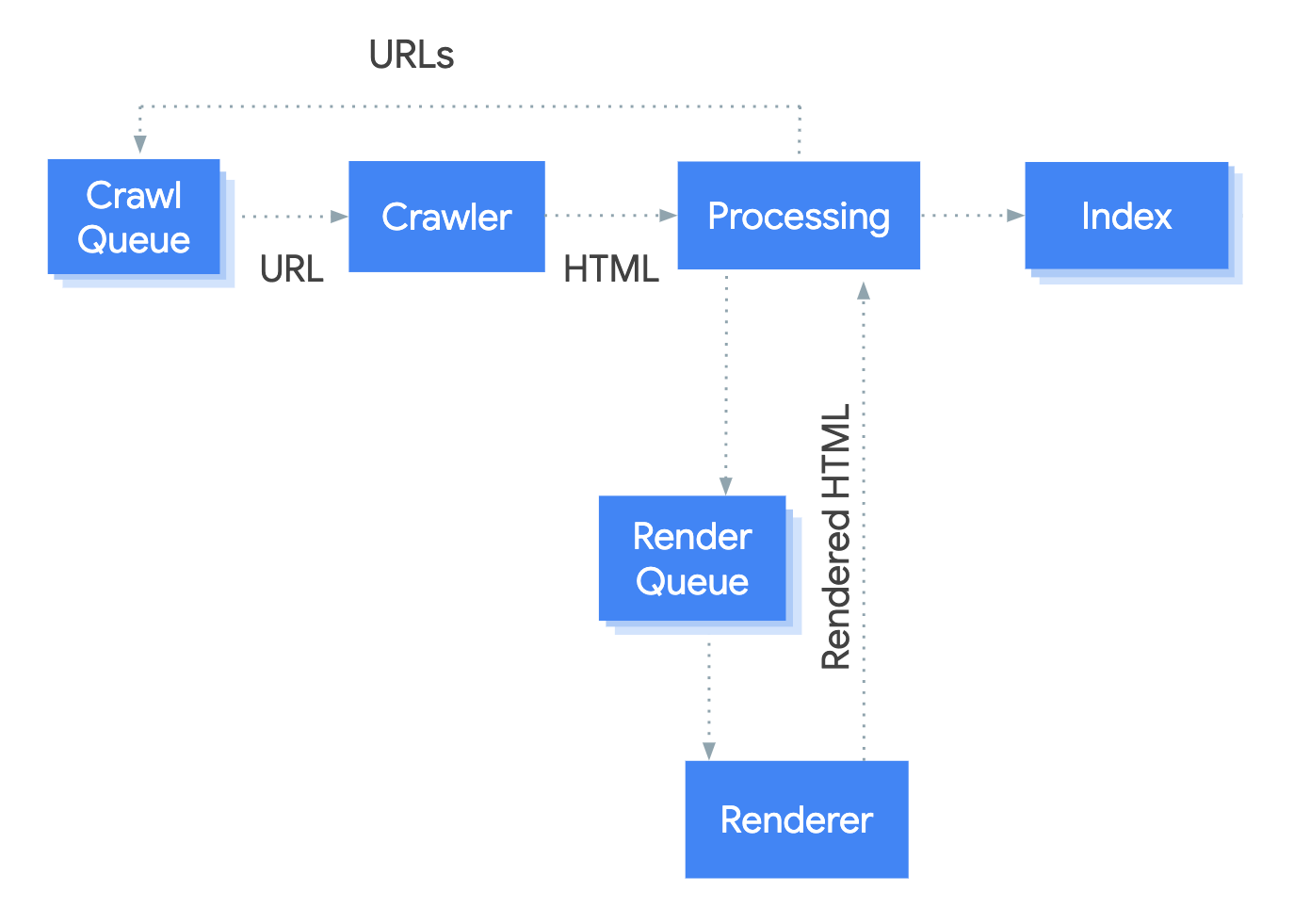
…but I noticed that the indexing data broke my mental models of how these processes worked over time.
Let me show you a couple of examples.
Submitted and Indexed > Crawled – currently not indexed
As I mentioned, pages reported as Indexed by Google can suddenly be reported as Excluded. All within 24 hours…without any warning.
Interestingly, based on the data, Google doesn’t need to immediately recrawl a URL to drop it from the index.
The pages that switched from Indexed > Excluded were last crawled between 1-6 months ago.
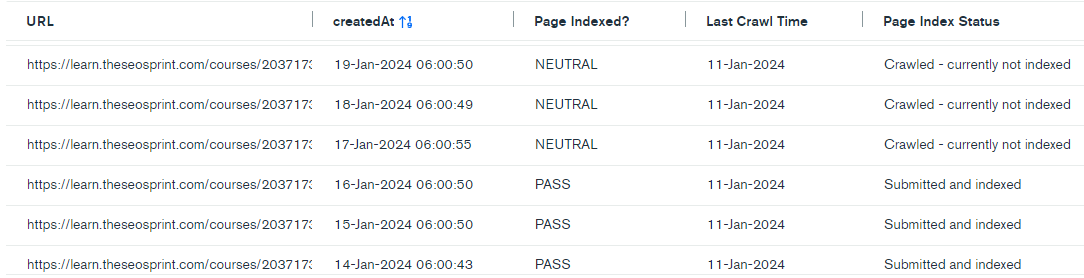
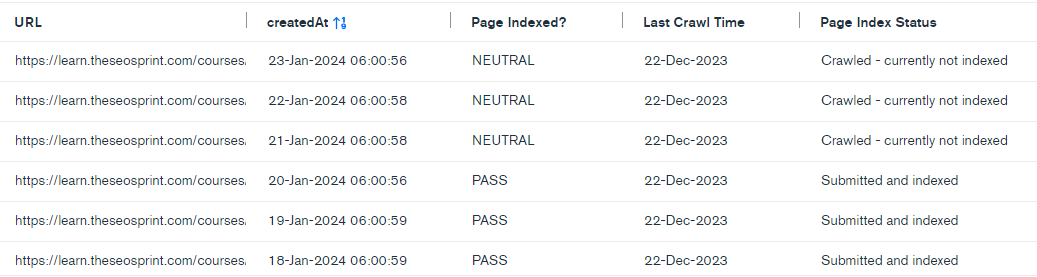
This indicates that Google’s algorithms take time to kick in and push out the URLs from the index. The process of crawling and indexing work independently of one another.
A page doesn’t need to be recrawled to get kicked out of the index.
Questions
A few questions rattling around my head:
- Is the last crawl time date accurate, or does it indicate something else is happening in the Googlebot system?
- Why do Google index pages that don’t meet quality standards slowly get kicked out over time?
- Are there clear signals that a page will get kicked out of the index, and can you report this to businesses?
- Is the URL inspection API indexing status data accurate for each URL (anecdotal evidence shows sometimes the data is inaccurate)?
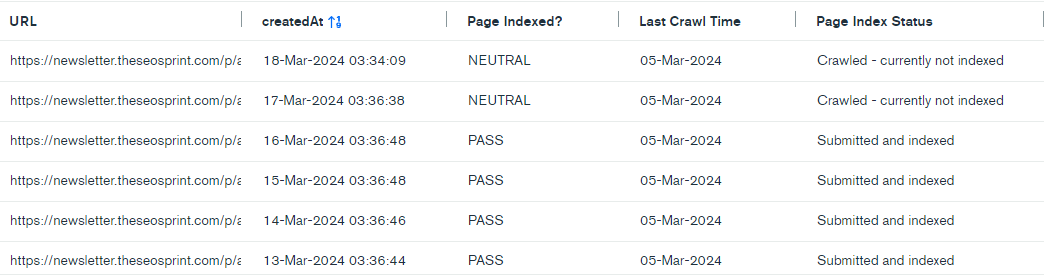
Noindex pages > Crawled – currently not indexed
Every SEO professional has seen the Excluded by ‘noindex’ tag in the page indexing report in Google Search Console.
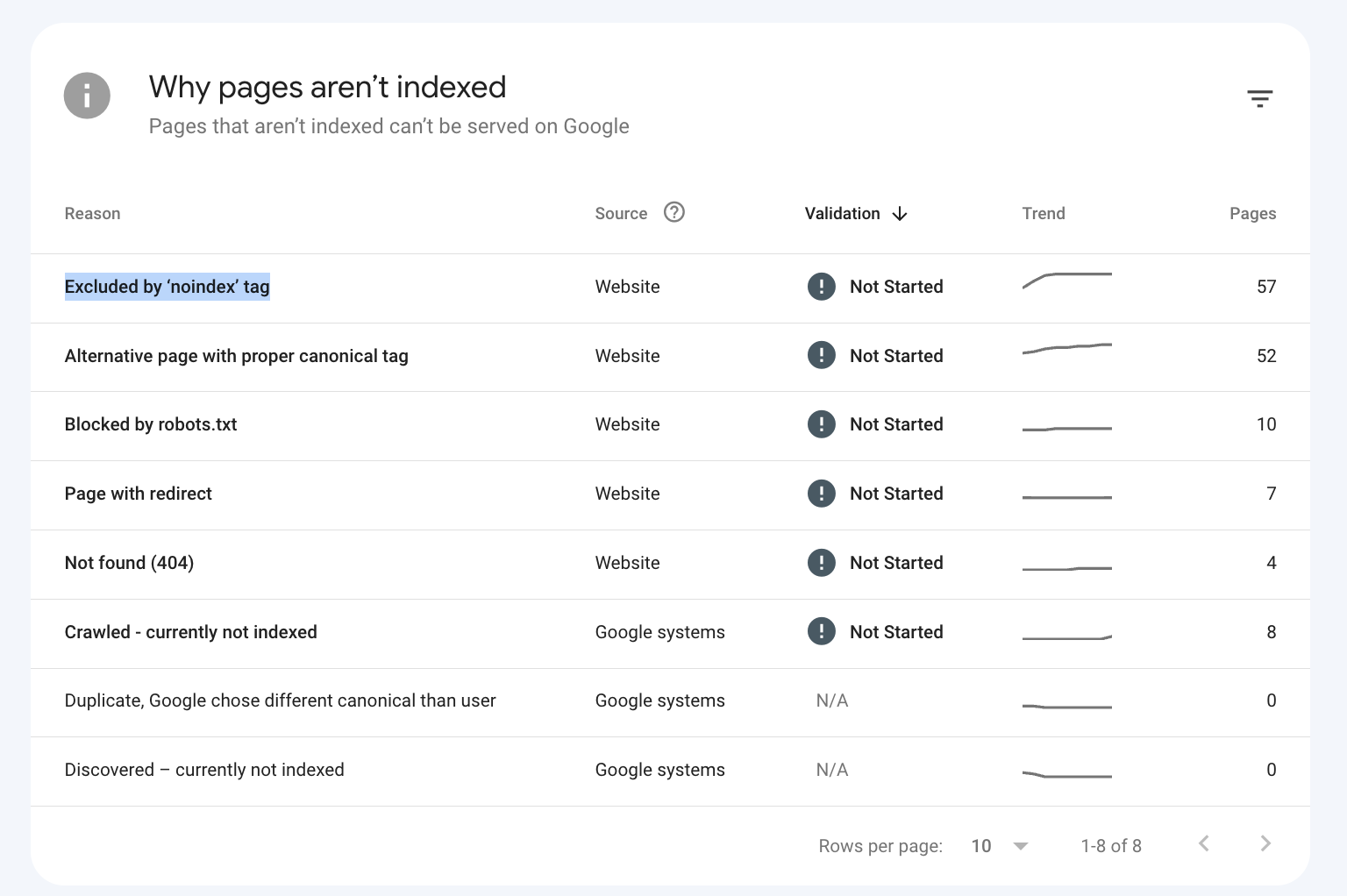
However, the indexing data over time showed me that pages don’t stay in this category. Pages Excluded by the ‘noindex’ tag can eventually be moved to “Crawled—currently not indexed.”
These pages are the comment URLs (example) on the substack platform.

This could be a reporting error. Not all the comments URLs are moving into the Crawled—they are currently not indexed. But I don’t think so.
SEO professionals have known for a while that pages with meta robots noindex will eventually turn into noindex, nofollow. John Meuller said the following in an office hangout eons ago:
“…if we see the noindex there for longer than we think this this page really doesn’t want to be used in search so we will remove it completely. And then we won’t follow the links anyway. So in noindex and follow is essentially kind of the same as a noindex, nofollow. There’s no really big difference there in the long run.” – Source
The URL Reporting API data shows us Google’s index behaviour when handling pages with a meta robots noindex tag. John Mueller describes how Google “removes it completely” if the noindex has been on the page for a long time.
If we check the indexing data of the comment URL over time, we can see that:
- The Last Crawl Time of the URL doesn’t change
- The canonical URL data gets removed completely
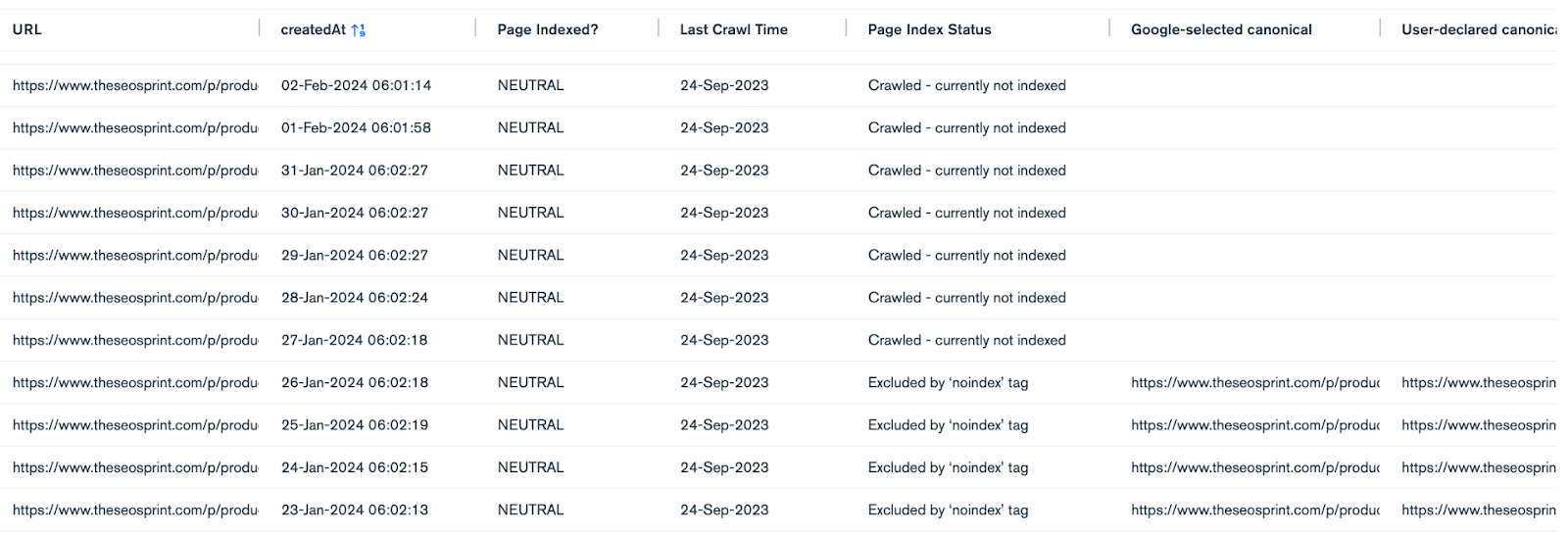
The switch happened on January 27, 2024, roughly six months after the last crawl time. This behaviour fits with that described by John Mueller regarding handling meta robots with noindex tags.
Questions
A few questions rattling around my head:
- Does the URL Inspection API accurately report what is happening in Google’s index?
- Can we actively measure other Google indexing behaviours to manage crawling and indexing on a website?
- Why are some noindexed pages moved to Crawled – currently not indexed category?
301 redirects help get pages crawled and indexed faster
I recently migrated all the content on www.theseosprint.com to newsletter.theseosprint.com.
As part of the migration I did some 301 redirect mapping. Out of curiosity I didn’t redirect all the URLs from the new URLs to the old URLs. Only the pages with traffic and backlinks.
I wanted to see what happened. Here is what I found using the historic indexing data:
- A new page URL with a redirect from a URL is crawled and indexed faster.
- A new page URL without a redirect takes weeks or months to be indexed.
For example, the following podcast URL (example) was redirected to the new newsletter.theseosprint.com equivalent.
Google picked up the redirect to the new URL quite quickly, and the URL’s index status was reflected in the GSC URL Inspection tool.

The migration to the new destination URL was quite seamless. The newsletter.theseosprint.com equivalent was crawled and indexed quickly.

In contrast, we see a very different story if we compare a podcast URL that was not redirected. The Craftsy and Custom Song podcast page URL (example) was allowed to return a 404.

The new newsletter.theseosprint.com podcast URL needed to be crawled or indexed when the new website was launched. Only after I manually requested the pages to be indexed in Search Console were they crawled and indexed by Google.

That means it took Googlebot over four weeks to crawl and index the page (migration was on 12 February 2024, and it was indexed on 16 March 2024).
A few notes about the website migration:
- The newsletter content was moved deeper into the website architecture (by 1 click).
- The main website uses WordPress, and the newsletter subdomain uses Substack.
- The only major change was the URL structure of the Substack content (www → newsletter)
The lesson from this data analysis is that redirecting URLs does more than just pass links and ranking signals. It can also help get your new pages crawled and indexed faster during a migration.
Questions
A few questions rattling around my head:
- Why is Googlebot not discovering or crawling new URLs that are submitted in an XML Sitemap AND is high up in the internal link architecture?
- Does redirecting old URLs to new URLs pass the page index status to the destination URL?
- Can you use this historic indexing data to flag when Google picked up redirects for important pages in a website migration project?
Googlebot log file data
The most surprising insight I gained from the historic indexing data from the URL Inspection API was that you could create a crawl stats analyser.
It’s not the same or as detailed as log files from your server. But it is a helpful middle ground.
The URL Inspection tool provides a Last Crawl Time metric for the pages you inspect. By creating metrics over time, you can understand when Googlebot crawls your most important pages.
Just like the indexing data, you can segment the data down to three levels:
- Website level
- Folder/subdomain level
- URL level
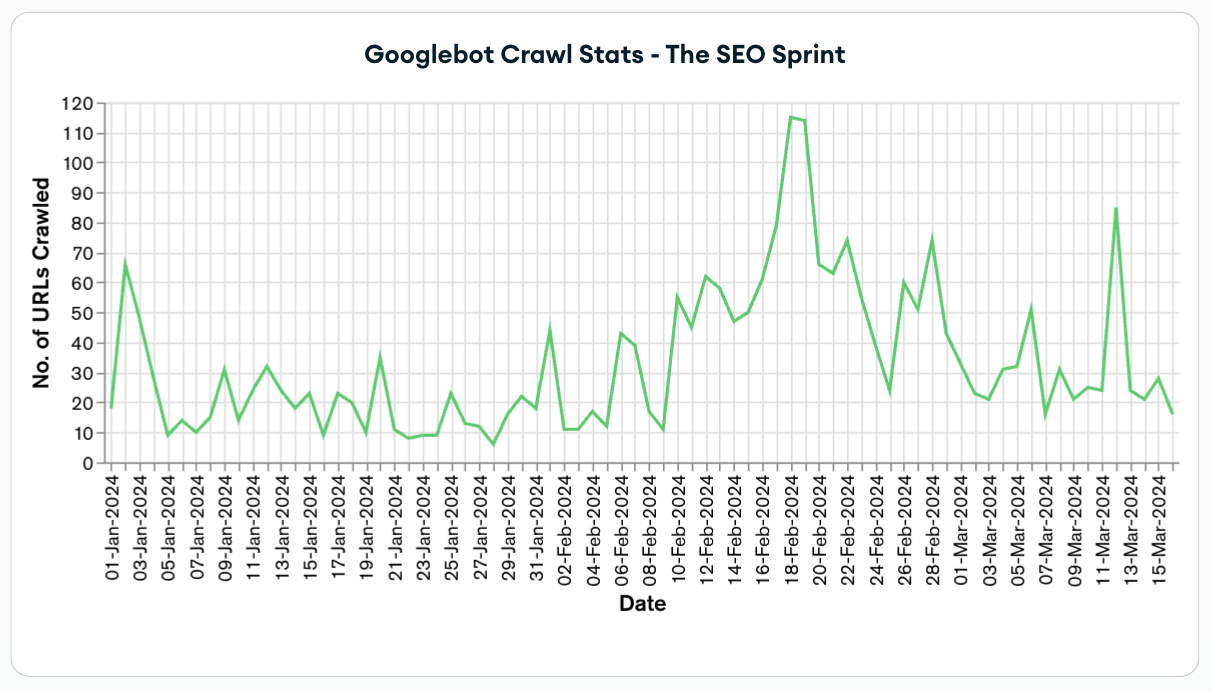
Google crawl stats – Website level
At a website level, I can see the crawl stats over time for the entire SEO Sprint website. You can see the spike in Googlebot crawling when the website was migrated.
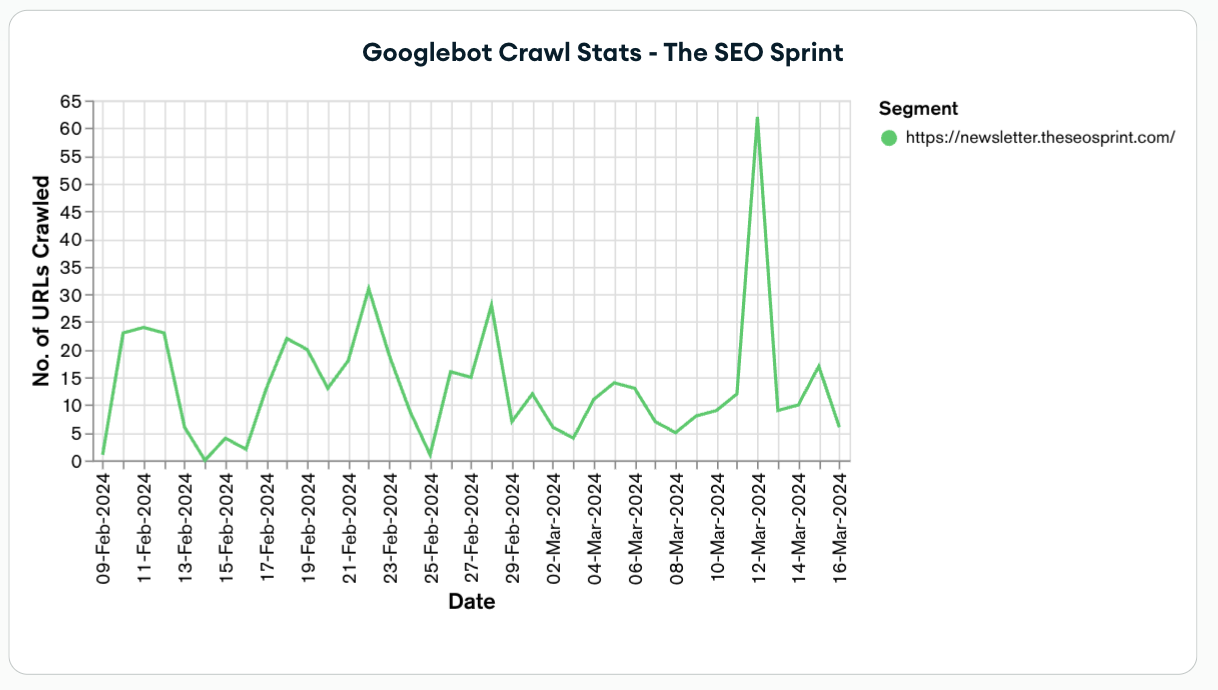
Google crawl stats – Folder/Subdomain level
You can see the website crawl stats data for a folder or subdomain on a website. Allowing you to spot trends in crawling for important pages within those site sections.
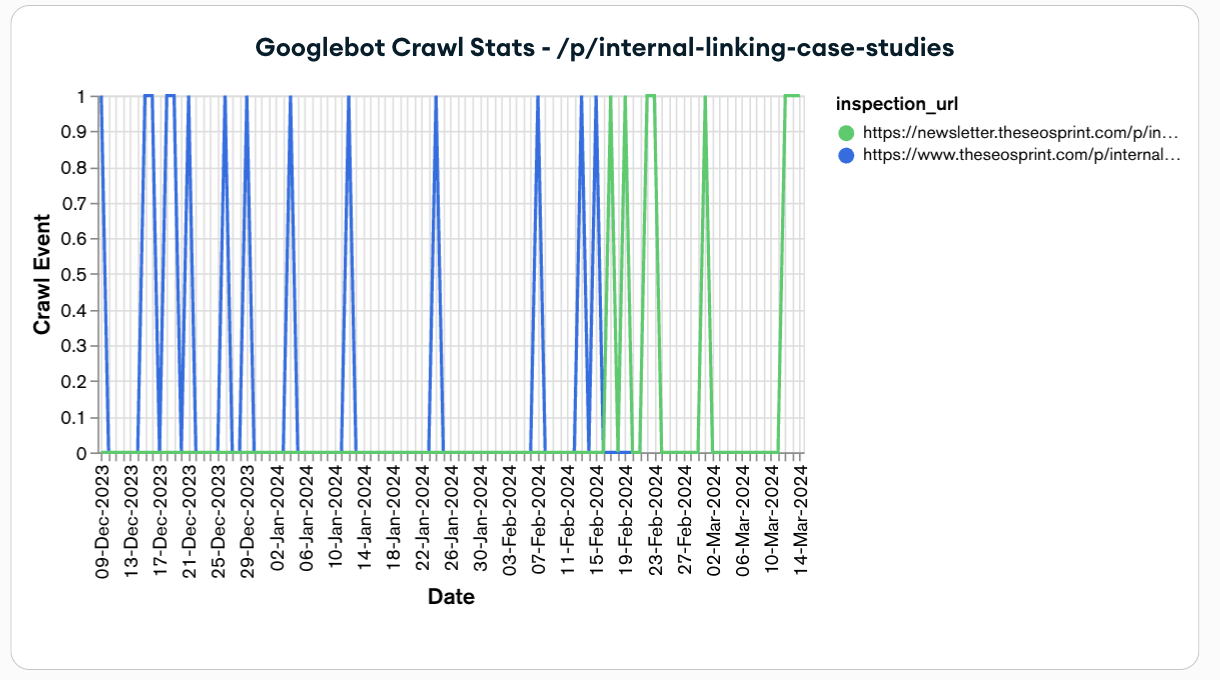
Google crawl stats – URL level
Finally, you can see the crawl stats on a URL level.
For example, the internal linking case studies post was redirected to the new destination URL. And you can see that Googlebot crawled the old URL quite frequently and with the redirect in place – the new destination URL is being crawled just as frequently.
Questions
A few questions rattling around my head:
- How accurate is the last crawl time data in the URL Inspection Tool?
- How can we run experiments and tests to understand the accuracy of the last crawl time data?
- Can crawl stats help SEO professionals gain useful insight into the crawling behaviour of Googlebot?
- Can the crawl stats date and XML Sitemap last modification date be combined to gain insight into when a page was published/crawled by Google?
Indexing monitoring at scale
Many of you ask a similar question: Can you monitor large websites with this tool?
The short answer is YES!
Let me quickly explain how we came to this conclusion.
The scaling problem with the URL Inspection API
One of the biggest problems and complaints about the URL Inspection API is the 2,000 limit.
In fact, if you go to any automatic Google indexing tool, you’ll see they all state that they can only check the indexing status of 2,000 URLs per day. This means that for large websites, checking the indexing status of pages at scale is a real problem.
Well, I wanted to see if I (and my dev partner) could solve this problem.
The programmtic SEO experiment
I needed to create a large website fast.
To do this, I created a very basic programmatic SEO website with 22,000 pages. The goal was to reduce the number of days it would take to fetch all the URLs in an XML Sitemap.
I even used Ian Nuttall’s URL Monitor tool to get the pages indexed automatically. To see if such things worked (it did). The result was a stair-like indexing graph in GSC. And what seems to be a dance between Google’s index and the indexing API.
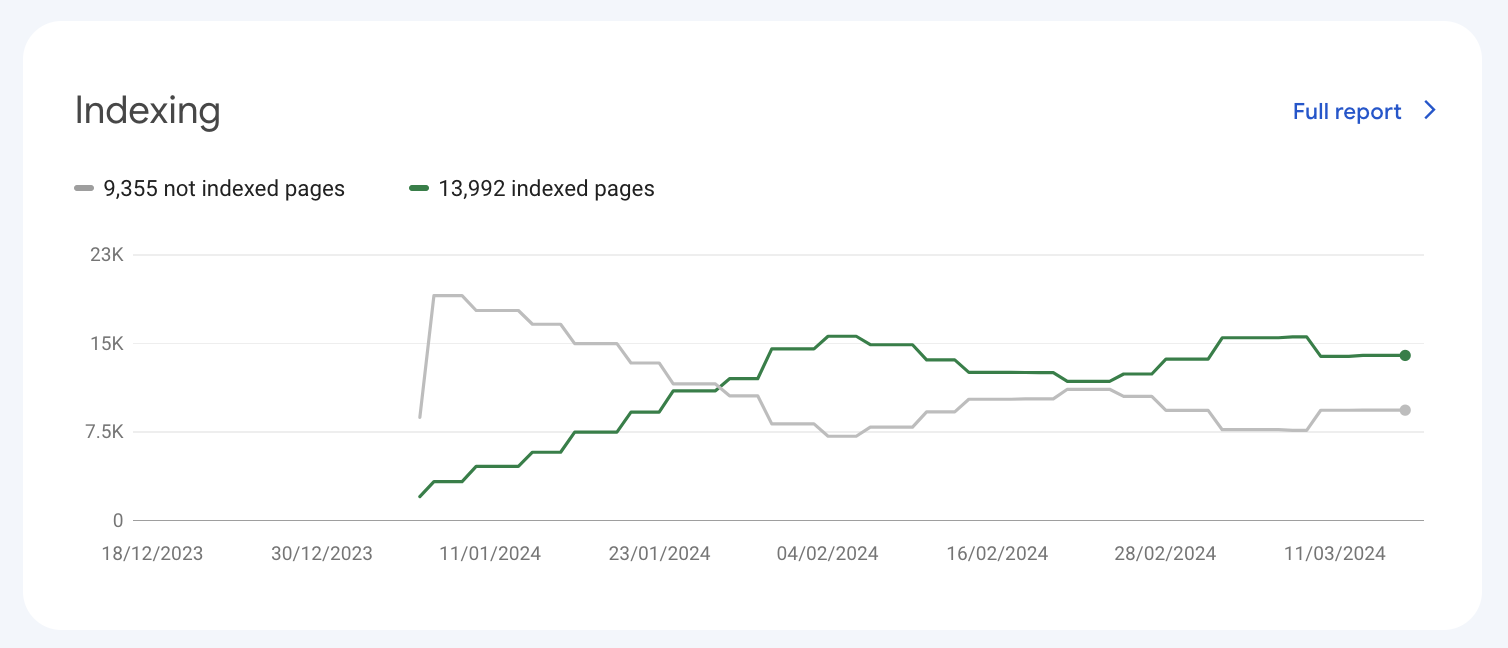
However, just like all other Google auto indexing tools it struggled to report on the indexing status of the number of URLs. Taking more than 30 days and using impression data to “guess” whether a page was indexed.
Cracking scaling the URL Inspection API
It didn’t take us long to crack the scaling problem of scaling the URL Inspection API.
I’m not going to tell you how we did it. Only that through fucking around and finding out were we able to crack it. And partnering with a clever senior developer always helps.
We even created a metric called the Inspection Cycle to tell how long it will take the scheduler to fetch the indexing status on all the submitted pages in an XML Sitemap.

For the programmatic website, it would take only 4 days to fetch all 22,320 pages. For most other tools with the 2,000 limit, it would take 12 days to fetch all the URLs (assuming they’ve figured out how to handle the error).
That’s x3 times faster than most other tools. But what about bigger websites with 100,000 or 500,000 URLs?
Well, I’ve done a few calculations, and theoretically, you could fetch 300,000 URLs within 30 days. You could get it down further, but it depends on your website and the setup of the GSC account.

This tool can’t handle millions of pages but can help most medium-sized SaaS, eCommerce, or listing websites. It could also help fetch key website sections of extremely large websites.
Alpha testing the indexing monitoring tool
This brings me to the final point of this long blog post.
I’m working with the development partner to build an alpha version of this tool. The tool itself is coming along, but there is still a lot of work to do.
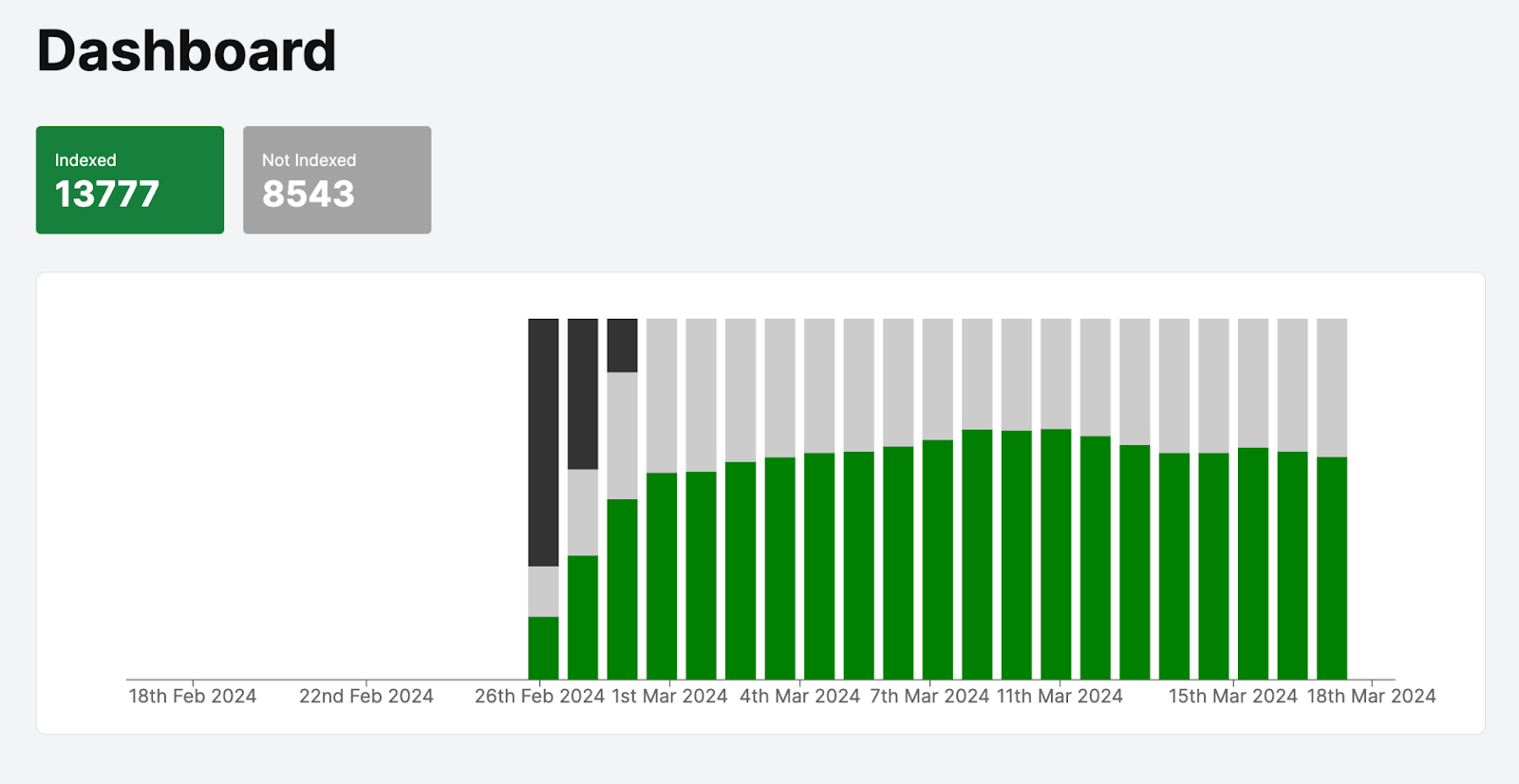
I’ve already got a list of SEO professionals who want to try it out. However, I’d like to know if you are interested in a SaaS tool that would monitor the indexing status of your website to help them identify crawling and indexing issues.
If you want to try the tool in the near future, enter your details below in the following form 👇.
Google Indexing Monitoring Survey
I can’t promise you’ll gain instant access to the tool, but it’s the easiest and fastest way to learn more about it and become a beta tester.
Thanks for making it to the end 😄.
Adam