
In this case study, I identified that Google was reporting on URLs blocked in the robots.txt file in the “Valid with warnings” report and how I resolved the problem very slowly.
TL; DR
In this experiment I learned that:
- Uncrawled URLs Policy – Google still clings to a 13-year-old policy to help websites display pages in SERPs that accidentally block important links to pages.
- Links matter (still) – Links are a key factor in displaying blocked URLs.
- Remove the links – Removing links to blocked URLs drops the uncrawled URLs from being displayed in Search and dropped them from the “Valid with warnings” report.
- It takes time – It can take months for Google to drop the uncrawled URLs from its search results and the “Valid with warnings” report (which is annoying).
The Problem
The development team made a release to a new platform and created a new sitewide parameter schedule-call?ref= URL across the website. It has a crawlable URL on every page.
It wasn’t a huge priority so myself and dev team agreed to block the parameter using the robots.txt file and not think about it.
But Google had other ideas.
A few weeks later GSC Index Coverage report started to display “Valid with warnings”.
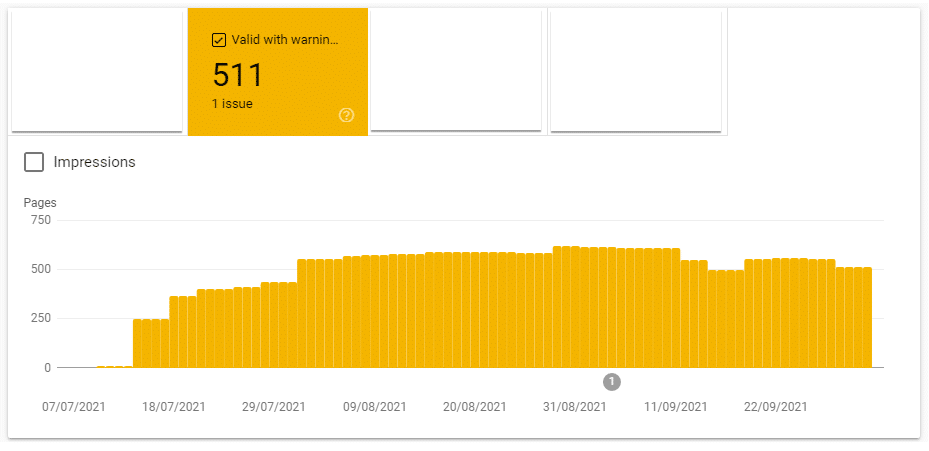
I was on holiday through August at the time so when I got back it had gotten to 500 URLs in the report.
When checking it appeared that Google was flagging the new crawlable /schedule-call?ref= URLs which had been recently blocked in the robots.txt file.
The developers (who I had educated on the wonders of GSC) raised this and wondered if it was an issue? Technically no but it was annoying that GSC reports were “flagging it”.
So, I decided to dig in and find a solution. This is what I found.
Blocked URLs showing in search results
In 2009 Matt Cutts (yes there was someone before John junior SEOs) did a video on why blocked URLs in the robots.txt were showing up in search.

“So even though they were using robots.txt to say, “You’re not allowed to crawl this page,” we still saw a lot of people linking into this page and they have the anchor text California DMV. So if someone comes to Google and they–they do the query, California DMV, it make sense that this is probably relevant to them. And we can return it even though we haven’t crawled the page. So that’s the particular policy reason why we can sometimes show uncrawled URL, because even though we didn’t fetch the URL itself, we still know from the anchor text of all the people that point to it that this is probably going to be a useful result.”Matt Cutts, 2009, Uncrawled URLs in search results
This video is now 13 years old (wait WHAT?!) but In the video, Matt talks about how the Google Search system has the policy to display “popular pages” which are well linked to other pages.
The question is this policy still in effect in 2022?
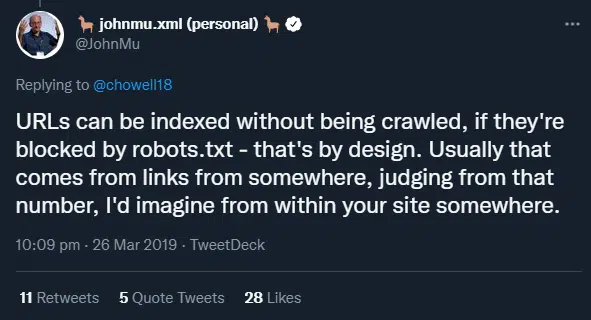
Well, the new Matt Cutts (Johnmu.xml) states exactly the same thing.
Also, if you check out Google’s documentation it also clearly states this:
“Indexed, though blocked by robots.txt: The page was indexed, despite being blocked by your website’s robots.txt file. Google always respects robots.txt, but this doesn’t necessarily prevent indexing if someone else links to your page. Google won’t request and crawl the page, but we can still index it, using the information from the page that links to your blocked page.”Index Coverage report Documentation
It is clear from both versions of Matt Cutts and Google’s own documentation is that the key factor in URLs being blocked by the robots.txt file appearing in “Valid with warnings” is links to the blocked pages.
How do we remove links to the blocked pages?
So, how do we use this information to solve the low priority issue “Valid with warning” report?
Simple, we remove the links to the blocked pages.
Luckily Google has already provided us with the tools to solve this “problem”:
- Nofollow tag – Add a nofollow tag to the links pointing to the blocked URLs.
- Create uncrawlable links – Do the opposite of best practice and make a href links the wrong sort of HTML link.
- Canonicalize or noindex the source page – The source page becomes non-indexable (noindex or canonicalised) where the uncrawlable link can be found.
All we have to do is to decide which technique to use.
The Fix
I ask the development team to implement a simple nofollow tag to the site-wide crawlable links which reference the /schedule-call?ref= parameter URL.
I then waited.
It took 2 weeks for Google to start dropping the number of parameter URLs from the “valid with warnings” report.

So, the solution of removing “crawlable” links to the blocked pages began to work.
The problem is I didn’t anticipate how long it would take for Google fully “resolve” the problem.

It has taken 10 months for Google to crawl and process these “uncrawlable” URLs (500 > 6 in “valid with warnings”) and drop them from Google Search.
This seems incredibly odd but sort of makes sense because the 500 URLs picked up were right after a platform migration. Googlebot is known for ramping up its crawling after detecting a sitewide change.
Summary – The Tale of Uncrawled URLs
There we have it.
The main thing I learned from this was:
- Google can display blocked URLs in the robots.txt in Search Console
- Google Search indexing system is still using a policy from 12 years ago
- Removing blocked URLs from Google’s link graph drops it from being displayed in the Search
- It can take a long time for Google to fully drop the URLs from Google’s search results.