
In this pointless crawl budget experiment, I blocked two resources that returned a 404 and 502 Googlebot spent a lot of time crawling each day.
TL; DR
In this experiment I learned:
- HTTP errors bring down average response time –
4xxand5xxerrors can bring down the average in crawl stats. - Blocking client and server errors can “increase” reported avg. response times – Blocking unimportant
4xxand5xxerrors can reveal the true average for your website in crawl stats report. - Page load resource higher crawl rate on lower priority sites – A high percentage (%) of page resource load resource UA requests might indicate that refresh and discovery crawling isn’t a priority for Googlebot on a particular host.
- Blocking URLs in robots.txt doesn’t shift crawl budget – Googlebot doesn’t reallocate or shift crawling to another area of the website just because you block unimportant resources (unless Googlebot is already hitting your site’s serving limit (which usually happens on large websites)).
Summary
Blocking unimportant resources can result in an “increase” in average server response time across the website.
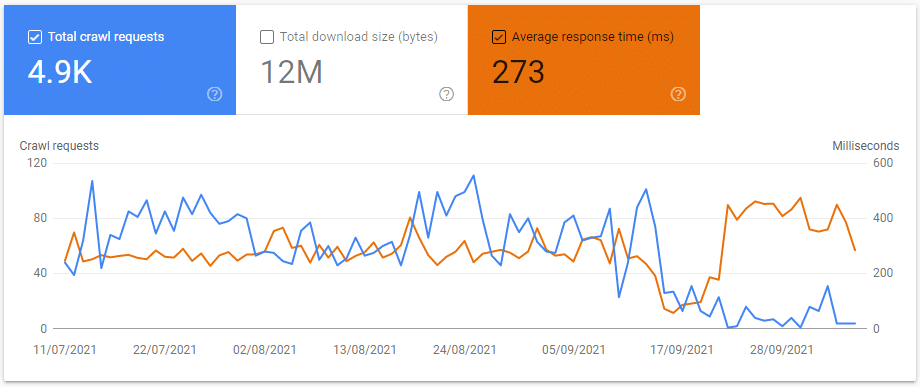
This is because the way that averages are calculated in Google Search Console and blocking the results revealed the true server response of my website (once Googlebot couldn’t access the two 4xx and 5xx resources pulling down the average).
I think this shows that if you have a large number of 4xx errors that take up a large amount of your crawl coverage, this can “pull down” your avg. server response time.
So, if you begin blocking unimportant resources this might cause the Crawl Stats Report to start showing your “true” server response time average.
This isn’t new information for most but just make sure that when judging things based on the Crawl Stats report just be aware of what is making up a large percentage of the requests.
Right onto the analysis and explanation of how I came to this conclusion.
The Problem
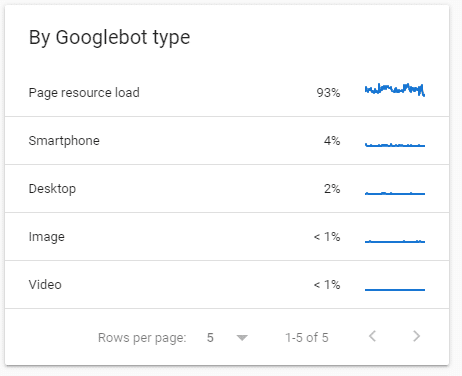
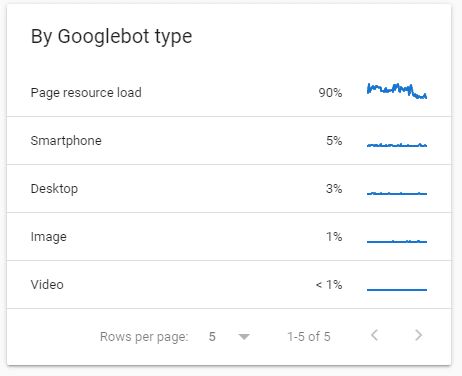
I noticed one day in the summer that the page load resource UA was eating up all the crawl budget (93%) on my tiny consultancy website in the last 90 days.
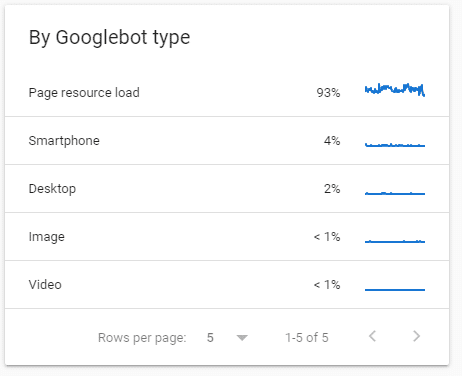
I found this odd considering that most of the website is cached behind Cloudflare and the pages WordPress I used has few resources per page.
When digging a little deeper it wasn’t a spike either it seemed to be consistent for the last 90 days.
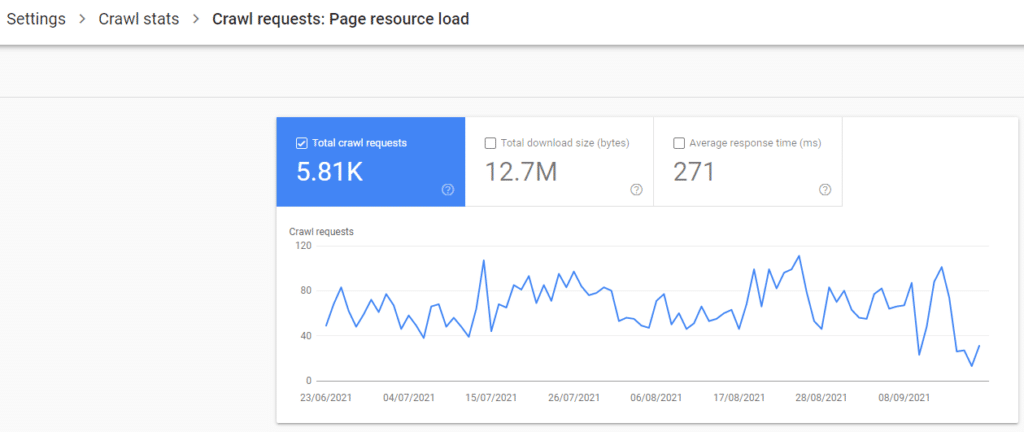
When drilling down into the URLs it was crawling it seemed that every day it was visiting a couple of 4xx .css and .js pages generated by a site speed plugin.

These were being caused by a web performance optimisation plugin which I had known about for a while but never really bothered fixing for various reasons.
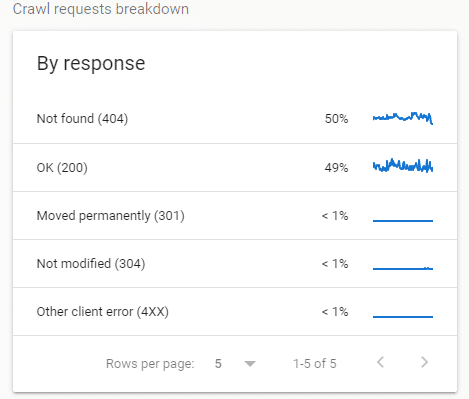
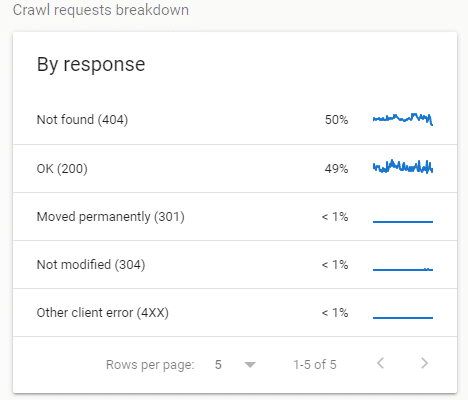
When checking the By Response report I found that 50% crawl coverage was caused by frequent visits to 404 client errors.
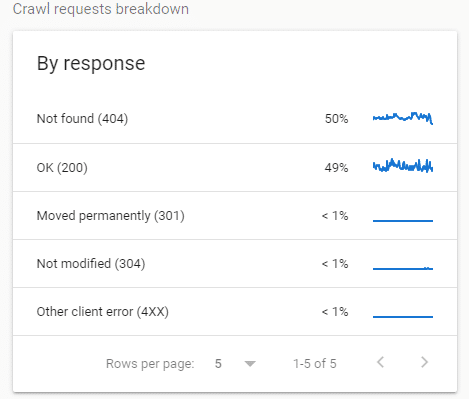
Of all the things to focus on it seemed odd that Googlebot and WRS focused their tiny crawl rate on .css and .js 404 errors.
Why would Googlebot focuses on 4xx non-critcal resources?
I asked myself this question from the beginning.
I know from talks given by software engineer and Martin Splitt that Googlebot’s system can prioritise crawling over fetching rendering resources (which I found it odd that page load resource UA was so high).

However, if a website isn’t frequently updated or authoritative website then the Web Rendering Services (WRS) must have more allocated resources to request URLs.
If there is very little discovery and refresh crawling (because my website is “meh”) then there would be more capacity for WRs to fetch resources.
Also, Martin has mentioned that Googlebot and WRS heavily cache resources. This might mean that WRS will keep asking Googlebot to fetch 4xx resources, to make sure those 4xx .css and .js files are not critical to rendering.

This meant that my Crawl Stats report was mainly reflecting Googlebots and WRS fascination with a couple of non-critical resources.
I was interested in what would happen if I blocked these 4xx and 5xx resource errors in the robots.txt. So, I ran a little test.
Hypothesis
I know from Google’s documentation that blocking URLs in robots.txt doesn’t “reallocate crawling to other parts of the website” as the blocked URLs stay in the scheduler. You need to actually work on improving your website and its pages to shift crawling focus to other areas of a site.
As I already mentioned, I don’t update my website regularly, produce content and it is very meh (for now). So, I don’t predict Googlebot will suddenly start increasing its crawl rate or even keep the same level of crawl requests but fetch a different set of URLs.
So, using this information I wrote down a few “assumptions” before I ran the test:
- Googlebot would not “increase” crawling for mobile or desktop UAs — as I haven’t improved the website and Googlebot doesn’t just “shift” crawling because you blocked URLs
- Googlebot would drop crawling on 404 errors
- Google Search Console crawl stats would see a overall % decline in 404 errors
- Google Search Console crawl stats would see a overall % increase in 200 status codes.
I told you this was a pointless but fun exercise but something happened that I didn’t predict.
The Test – Blocking 4xx URLs
I blocked the two resources in the robots.txt as I wanted to understand the impact on the crawl budget (if anything).
User-agent: Googlebot
Disallow: /wp-content/cache/autoptimize/css/
Disallow: /cdn-cgi/rum
Sitemap: <https://gentofsearch.com/sitemap_index.xml>
I checked that blocked resources weren’t impacting Google’s ability to render the page.
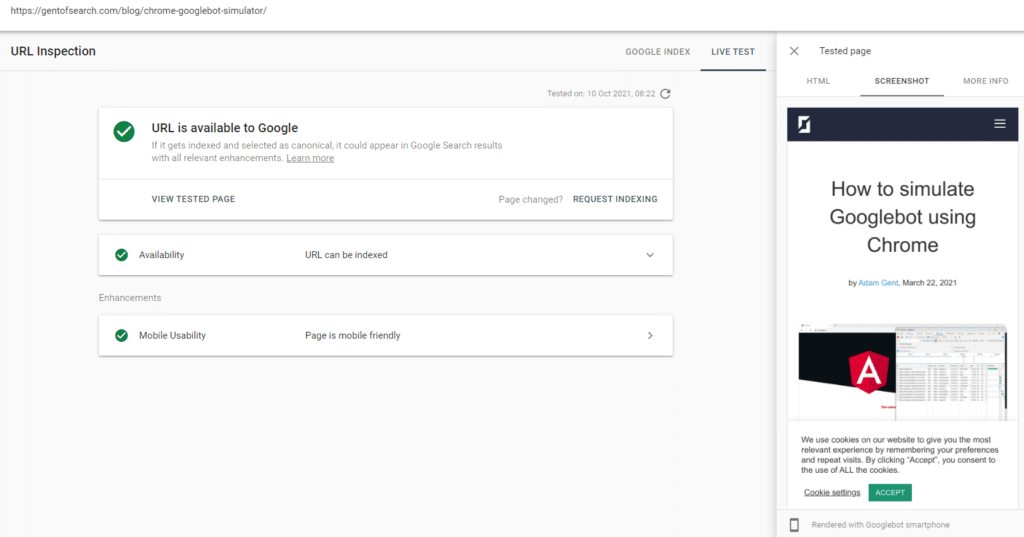
I made sure the resources were blocked in the More Info > Page resources tab in the Google Search Console URL Inspection tool.
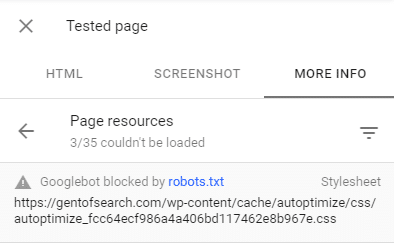
The Result – 1-2 Days
I had to wait for 48 hours before Google recached the robots.txt file and Google Search Console updated the crawl stats report.
This is what I found.
Average Response Time Dropped
In the first 2 days, the average response time dropped from 300 ms to 100 ms. This was the most surprising result of blocking these two resources.
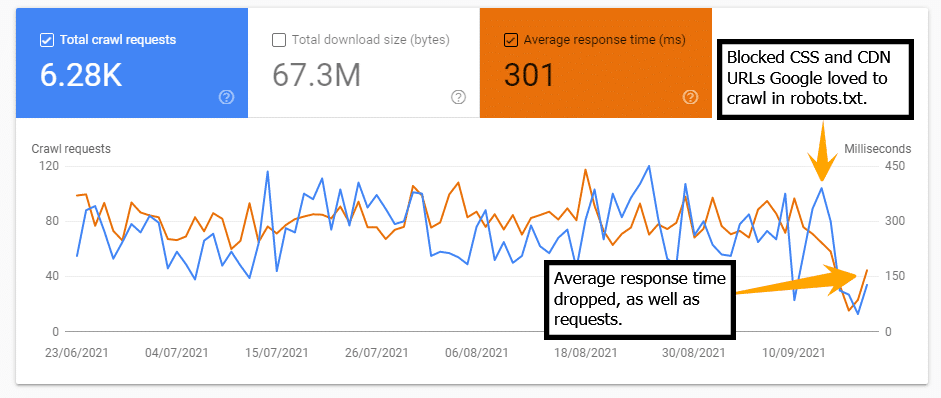
Before you start blocking things to reduce server response time keep reading, this is where it gets interesting.
4xx Crawled Dropped to Zero
The requests to 4xx errors dropped to zero or almost nothing.
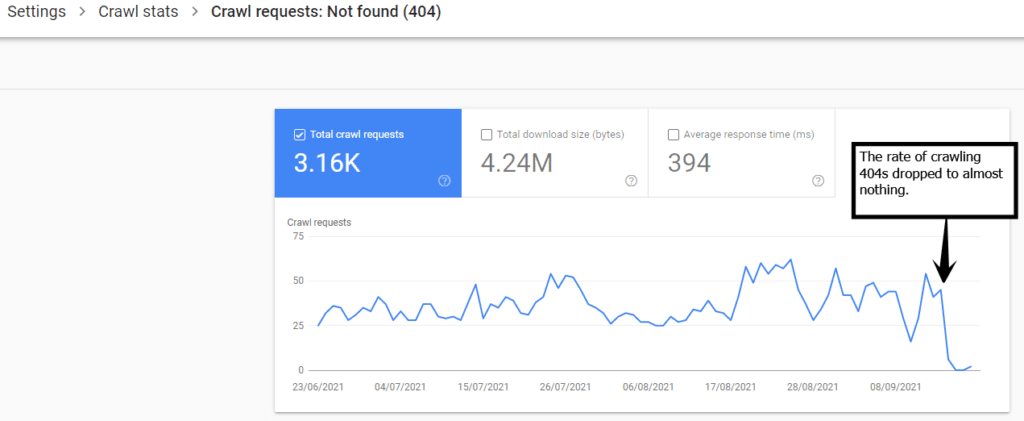
Over time I predict that there will be a greater percentage (%) of 200 (OK) URLs crawled overall as the number of Not Found (404) crawled has dropped.
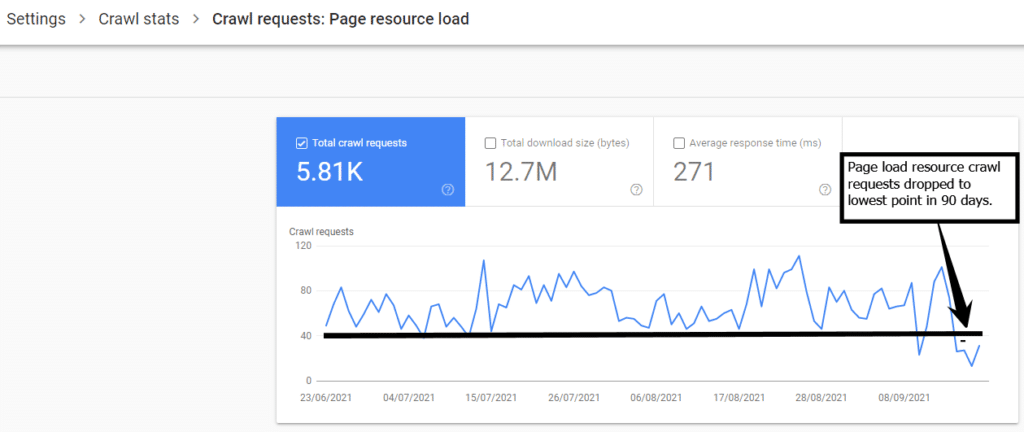
Page load resource dropped
The total crawl requests from the page load resource UA was at their lowest after blocking the 404 resource URLs in the first 1-2 days.
Again, I predict that after a while the percentage (%) of Googlebot Smartphone UA types will increase because there are fewer page load resource UA requests overall.
The Result – 21 Days
I waited 21 days to see if there were any changes and I was quite surprised by the results (but now I think about it makes sense).
Average Response Time Almost Doubled
After 30 days I was quite surprised to see that the average server response time nearly reach 600 ms from an avg. of 250 ms before I blocked the resources.
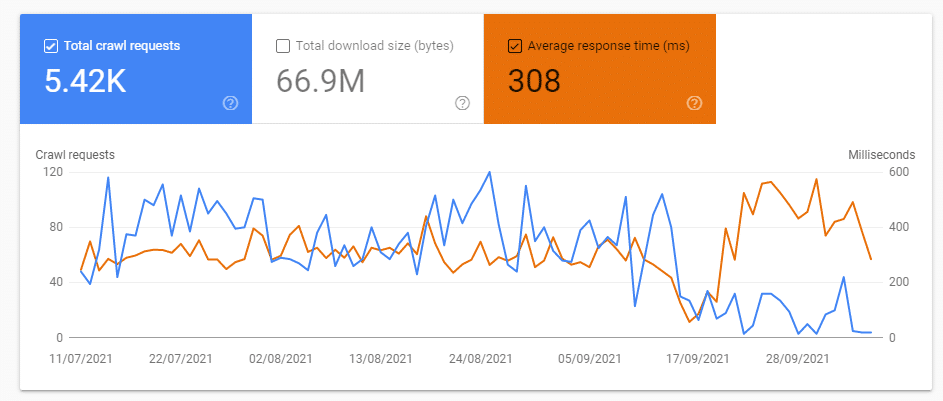
As you can see the average server response almost doubled. This wasn’t a surprise considering the page resource load UA (90% of requests) response time increased.
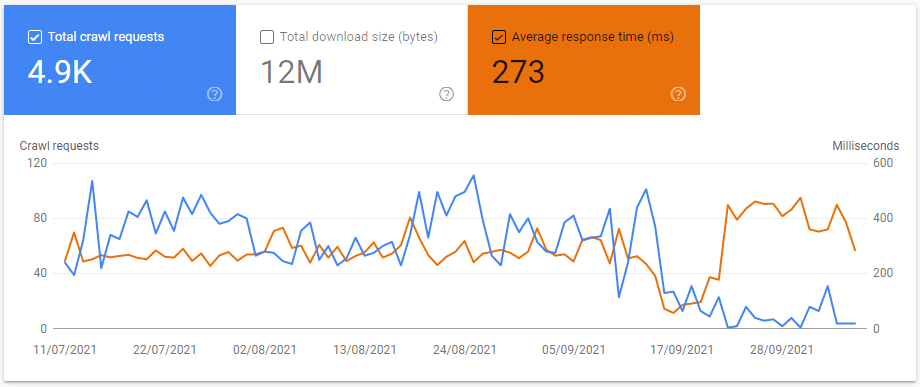
This is likely due to the 4xx and 5xx server responses fetched every day no longer “pulling down” the average.
4xx crawl requests didn’t increase
Googlebot didn’t increase its number of requests to other 4xx errors and this status type continued to be almost nothing.
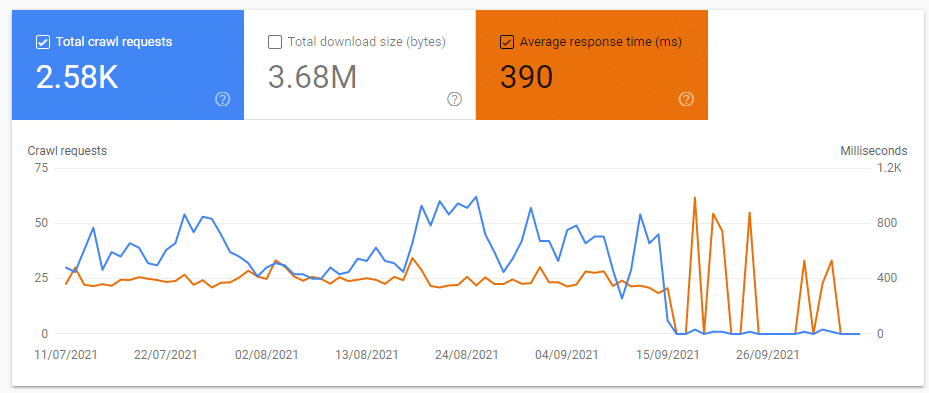
I did find it interesting that old experiment URLs that were now 404 errors seemed to now have a greater server response when compared to the resource URLs.
I might need to look into why when I get a chance or do something else with them (301?).
Also, as I predicted the number of OK (200) page percentage increased and Not Found (404) decreased based on how the Crawl Stats reports on the data.
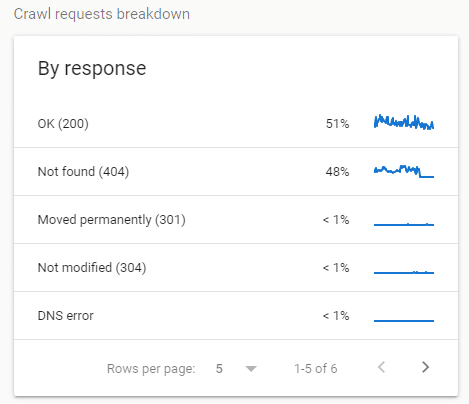
Page Load Resource UA continued to drop
The total crawl requests from the page load resource UA continued to decline and is still at their lowest.
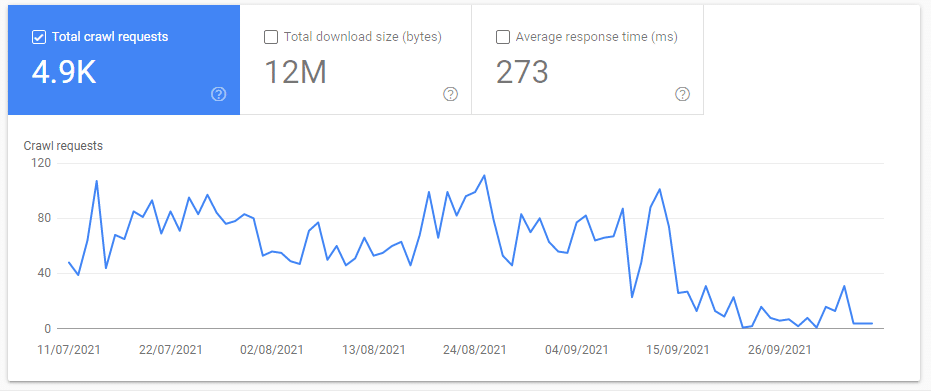
As I predicted the percentage (%) of Googlebot Smartphone UA type decreased and Googlebot Smartphone % increased because there are fewer page load resource UA requests overall.
What was the impact on traffic?
I didn’t notice any change in clicks or impressions in Google Search.
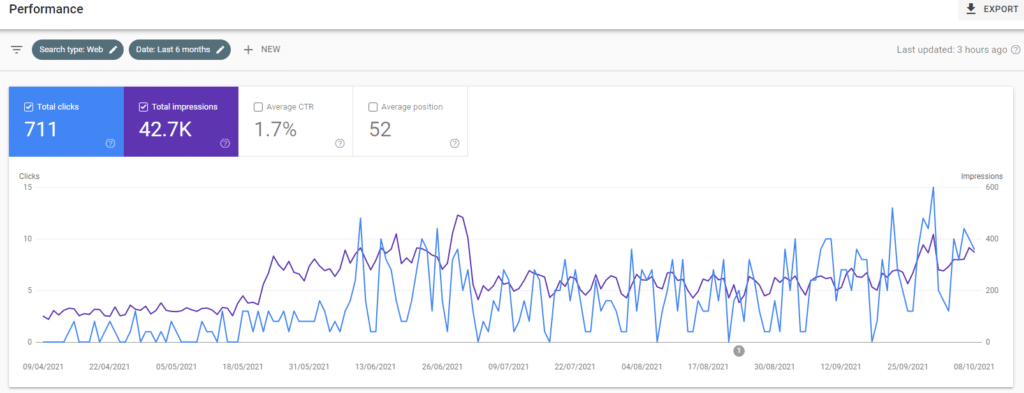
I did run a small experiment with Zyppy Cloudflare title tag tool at the end of September-21 to change a title tag for one of my pages which is ranking for keywords.
This did result in a positive change in traffic to that page but apart from that, there was no real change.
What did I learn?
As I said, this experiment was a bit pointless if you’re wanting to “increase crawl budget” for a website.
However, if you are interested in understanding more how Google’s reports and Googlebot reacts when you bock unimportant resources it might be useful.
I’ve no idea how you’d use this information but from this experiment, I learned that:
4xxand5xxerrors can bring down the average in crawl stats.- Blocking unimportant
4xxand5xxerrors can reveal the true average for your website. - A high percentage (%) of page resource load resource UA requests might indiciate that refresh and discovery crawling isn’t a priority for Googlebot on a particular host (likely due to a website that doesn’t frequently update or isn’t authoritative).
- Googlebot doesn’t reallocate or shift crawling to another area of the website just because you block unimportant resources.
Do what you want with this information and as usual, it all depends on your website.